Pilot Data: Which Phishing Techniques Actually Fool People?
Pilot data from 56 participants in Threat Terminal reveals which phishing techniques humans miss most when AI eliminates writing quality as a signal.
Most phishing training is built around a detection signal that no longer works. Spot the grammar error. Look for the urgency. Check the sender domain. These heuristics held up for years because real phishing campaigns were sloppy. Now they are not. AI-generated phishing is grammatically flawless, contextually plausible, and available at scale. The old tells are gone.
Two weeks ago I wrote about the design behind Threat Terminal, a retro terminal game built to study exactly this problem. The study is live and collecting data. This post is about what the pilot data is showing so far.
The Numbers
56 participants. 817 email classifications. Every card in Threat Terminal is AI-generated, phishing and legitimate alike, so writing quality is held constant across the board. Technique is the only independent variable.
Here is the overall picture: participants correctly classified 87.3% of emails. Phishing detection rate was 85.5%. Legitimate emails were correctly identified 91.6% of the time. Those are decent numbers on the surface. The interesting part is where the errors cluster.
Technique Matters More Than You Think
Not all phishing techniques are equally effective against humans. The miss rates by technique tell a clear story:
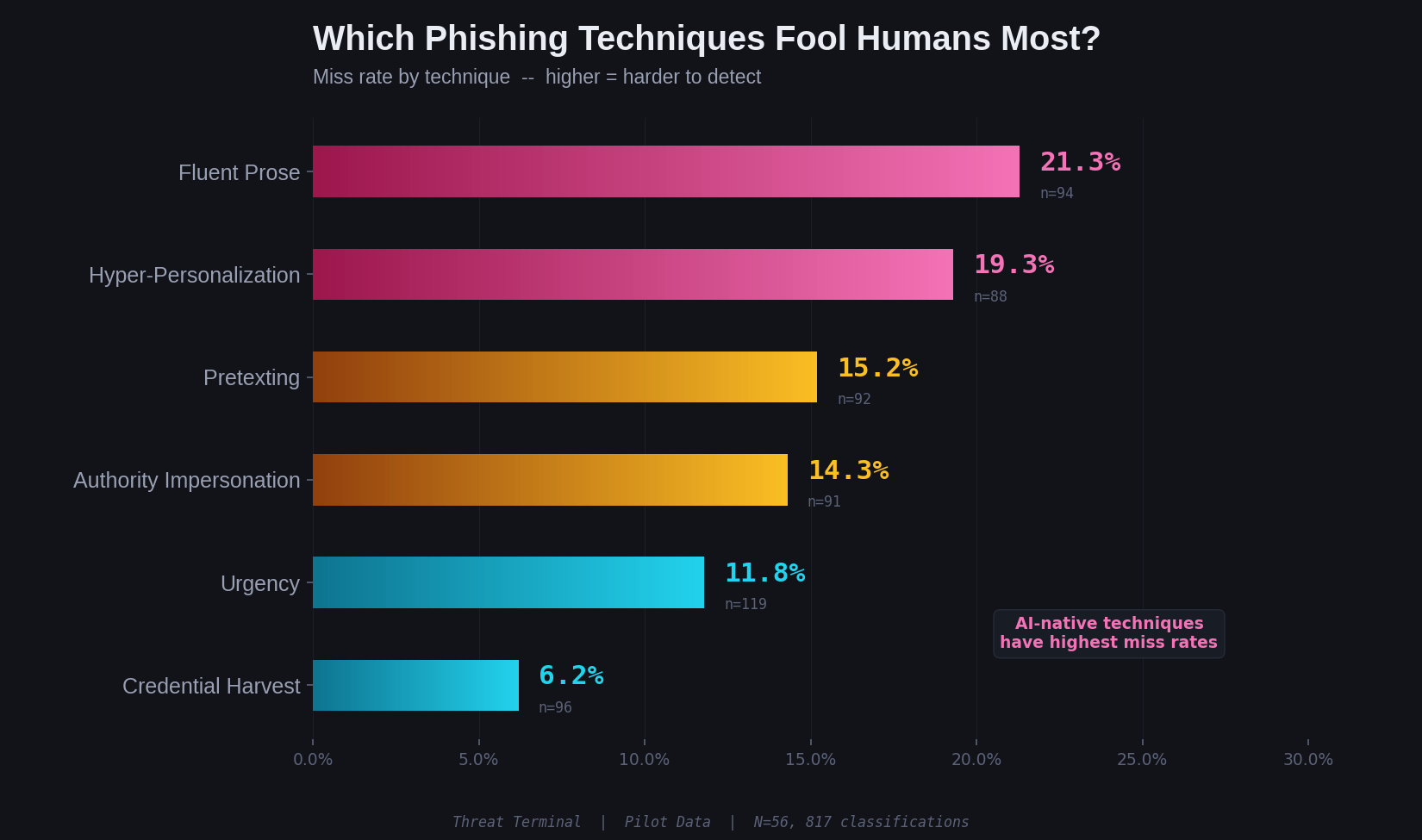
Fluent prose, phishing with no urgency cues, no authority figure, no personalization, just polished neutral email language, had a 21.3% miss rate. One in five. It was the hardest technique for participants to detect.
Hyper-personalization came second at 19.3%. Emails referencing contextually plausible personal or professional detail fooled roughly one in five people.
Credential harvesting, the technique most security awareness training focuses on, had a 6.2% miss rate. People are good at catching "click here to verify your account." They are not good at catching an email that simply sounds like a real person wrote it.
The two techniques most enhanced by generative AI, fluent prose and hyper-personalization, are the two humans are worst at detecting. The techniques that rely on older, cruder tactics are caught at much higher rates.
The Authentication Problem
This one surprised me.
In practice, SPF/DKIM/DMARC failures are caught by email filters before a human ever sees the message. Most users never need to check authentication headers. Threat Terminal surfaces these signals deliberately because the study's audience skews toward security professionals, and one of the research questions is whether security-trained players anchor on authentication status when evaluating emails.
The pilot data suggests they do.
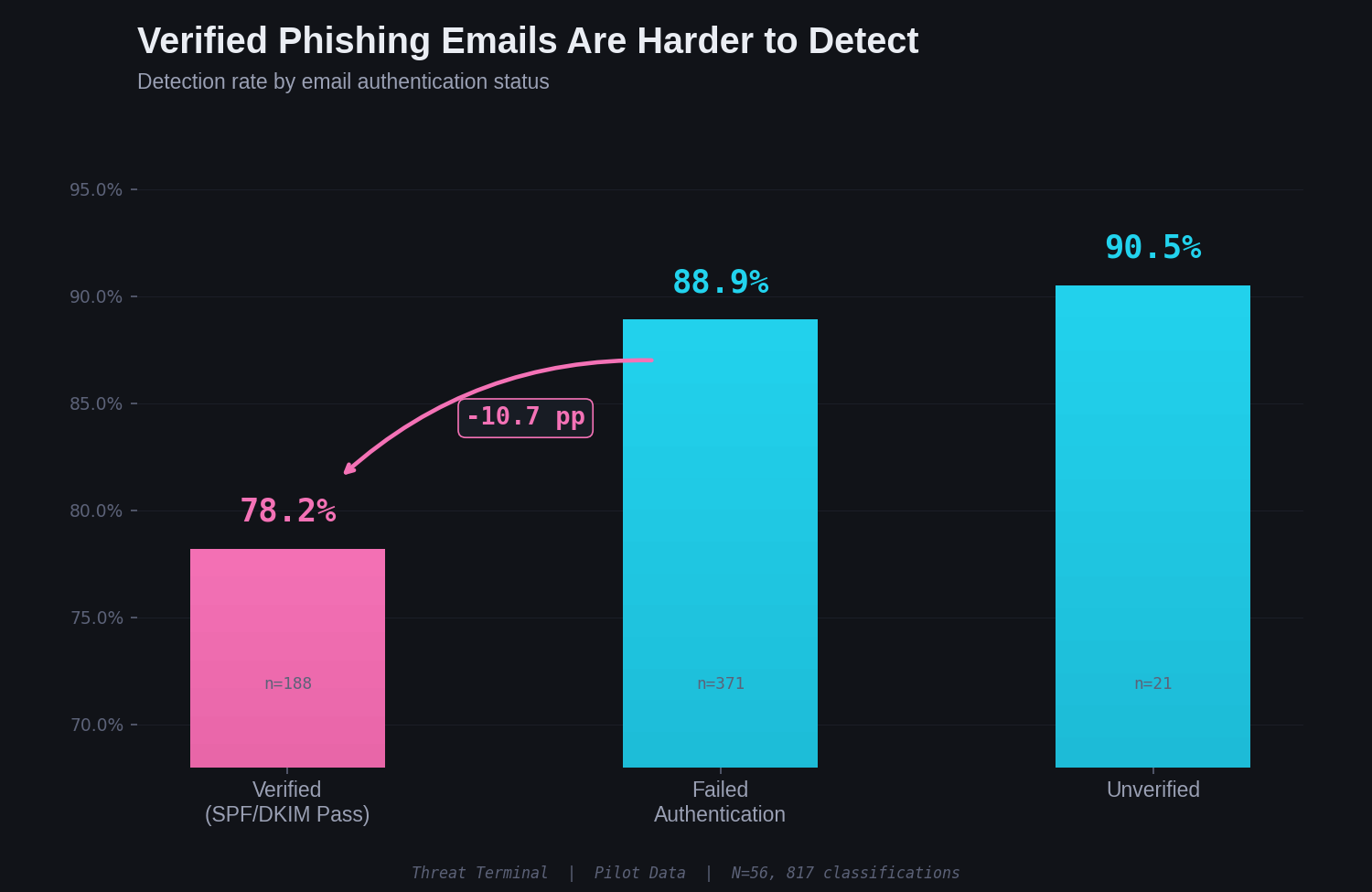
Phishing emails that passed authentication were detected at only 78.2%. Phishing emails that failed authentication were detected at 88.9%. That is a 10.7 percentage point drop in detection when the email carries a verified badge.
Players who saw passing authentication headers appear to have treated that as a legitimacy signal, even on phishing emails. This is a known behavior in security operations: authentication pass is not proof of sender legitimacy, but it functions as one psychologically. Attackers who control a domain and configure SPF/DKIM properly get a trust signal for free.
Overconfidence Is a Vulnerability
Threat Terminal captures self-reported confidence on every classification. Participants select guessing, likely, or certain after each answer. This creates a direct measure of calibration: are people right when they think they are right?
Mostly, yes. But the failures are revealing.
8% of participants who said "certain" were wrong. Of those 47 overconfident-wrong answers, 38 were phishing emails the person was certain were safe. Only 9 were legitimate emails flagged as phishing. The overconfidence problem is asymmetric. When people are confidently wrong, they are almost always letting phishing through, not blocking legitimate email.

Time Does Not Help
You might expect that participants who spent more time on a classification would be more accurate. The opposite is true.
Correct answers had a median response time of 37.9 seconds. Wrong answers had a median of 51.3 seconds. People who hesitated longer were more likely to get it wrong. This does not mean speed causes accuracy. It more likely means that ambiguous emails produce both hesitation and errors. But it does undermine the common advice to "slow down and think carefully." The data suggests that when you need to slow down, the email has already won.
Difficulty Validation
Threat Terminal assigns a difficulty tier to each card: easy, medium, hard, extreme. The pilot data validates that these tiers are working as intended:
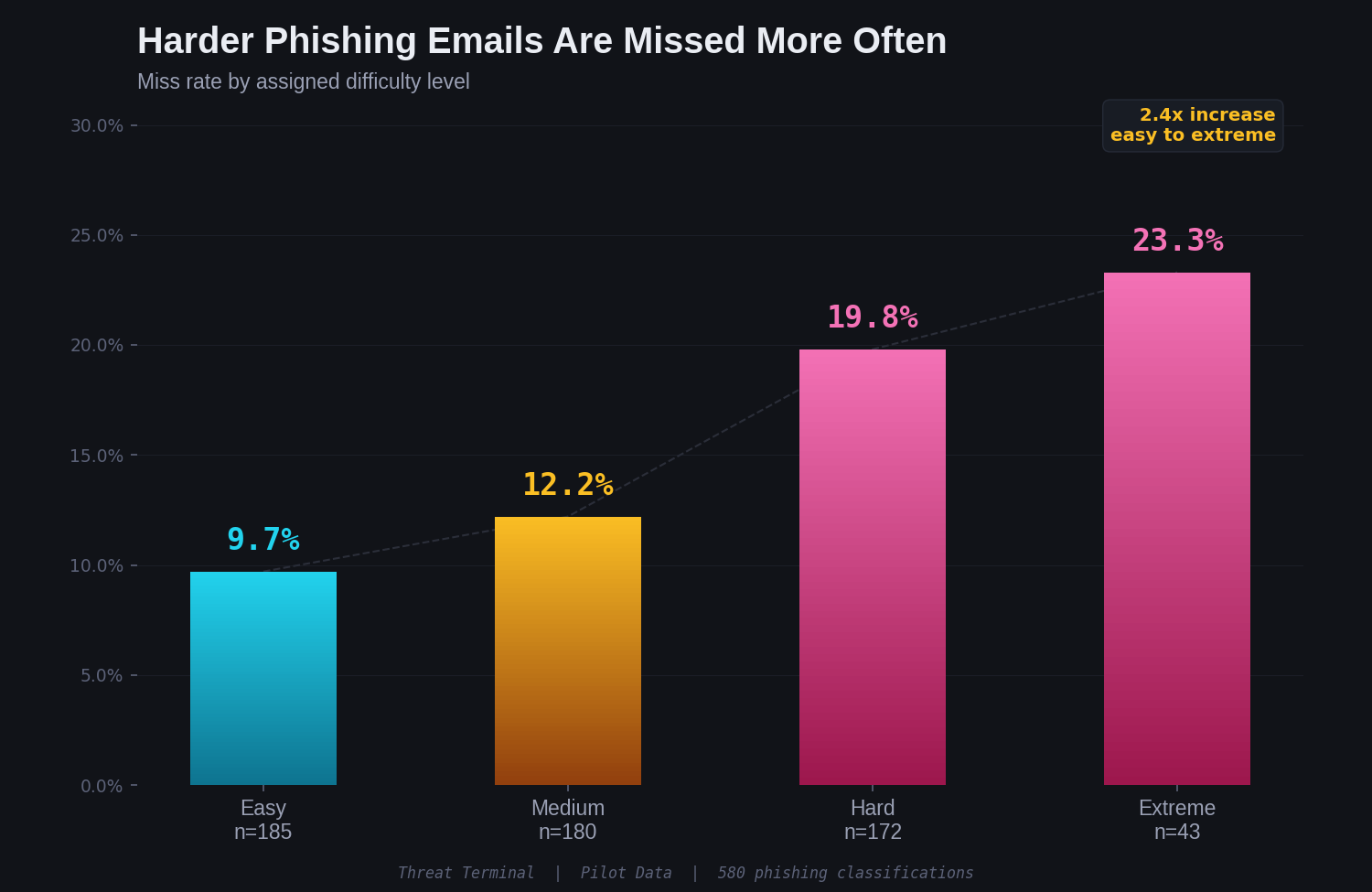
Miss rates scale cleanly from 9.7% at easy to 23.3% at extreme. That is a 2.4x increase. The difficulty model is producing a measurable gradient in human performance, which matters for the instrument's validity as we scale toward a larger dataset.
What This Does Not Tell You
This is pilot data from 56 participants in an ongoing study. The accompanying academic paper is a protocol document: it describes the methodology and instrument, validated by this initial cohort. It is not a findings paper making conclusive claims.
The sample skews toward people interested in cybersecurity. 35% self-reported an infosec background. That likely means these numbers are optimistic. A general population sample would probably perform worse.
The dataset is not yet large enough for robust subgroup analysis. I can see that infosec participants scored 87.9% and non-technical participants scored 83.4%, but I am not making strong claims about background effects until the sample is larger.
What Comes Next
Data collection is ongoing at research.scottaltiparmak.com. A protocol paper describing the methodology is in progress. The raw dataset will eventually be published for independent analysis.
If you work in security awareness training, the early signal here is worth paying attention to. The phishing techniques your training focuses on, credential harvesting, urgency, are the ones humans are already good at catching. The techniques your training probably ignores, fluent prose, hyper-personalization, are the ones that get through.
The old tells are gone. The question is what replaces them.
Try it yourself: research.scottaltiparmak.com
More posts
The Action Pause: A 10-Second Habit for AI-Era Impersonation
A behavioral framework for AI-era impersonation across email, voice, video, chat, and in-person asks. Empirically grounded in 2,511 classifications from the Threat Terminal study. Trigger on the action request, not on the content.
Preliminary Findings: How Humans Detect AI-Generated Phishing Across 2,511 Classifications
Findings from 153 participants classifying AI-generated phishing: technique-level bypass rates, overconfidence patterns, and what security training misses.
Stay in the loop
I write about the security topics that interest me: IAM, cloud security, automation, threat intelligence, phishing, and incident response. If this was useful, there is more where it came from.